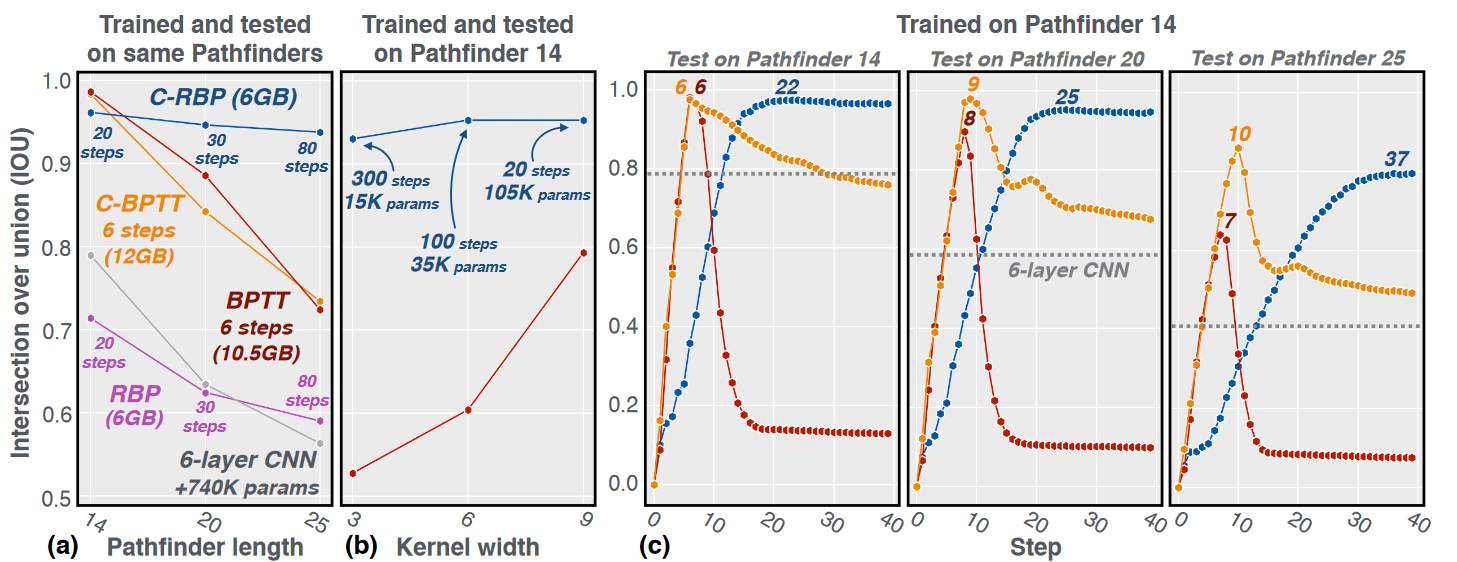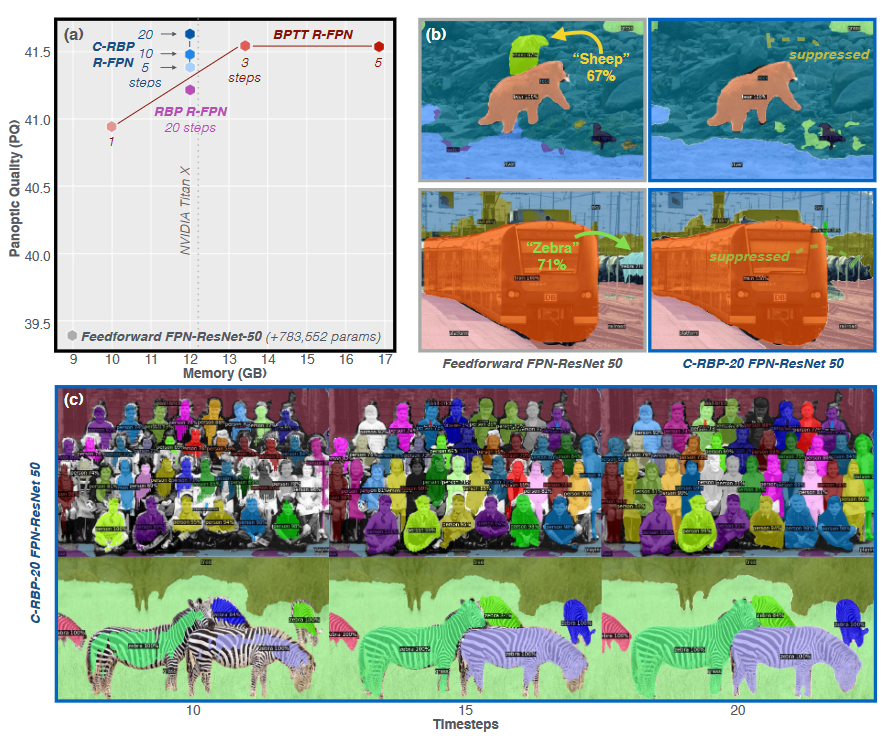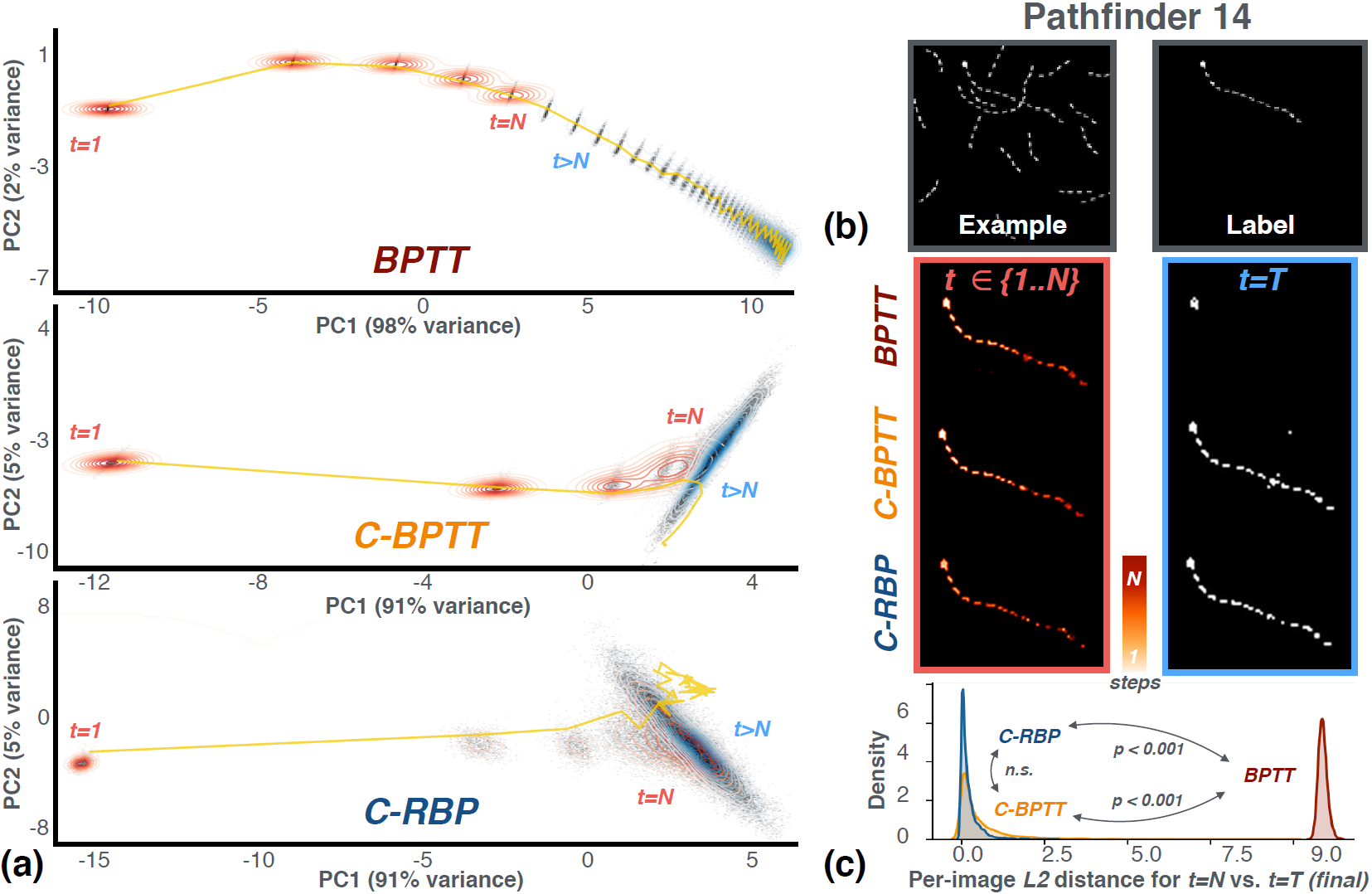
Figure 1: Recurrent CNNs trained with backpropagation through time (BPTT) have unstable dynamics and forget task information. This pathology is corrected by our Lipschitz Coefficient Penalty (LCP). (a) Visualization of horizontal gated unit (hGRU) state spaces. Models were trained on Pathfinder-14, and state spaces were visualized by projecting hidden states onto each model's top-two eigenvectors. Grey dots are the 2D-histogram of projected hidden states, red contours are hidden state densities up to the task-optimized N steps, and blue contours are hidden state densities beyond that point (t>N, for 40 steps). Exemplar dynamics for a single image are plotted in yellow. While dynamics of the BPTT-trained model diverge when t>N, models trained with LCP did not. We refer to the learning algorithms of LCP-trained models as contractor-BPTT (C-BPTT) and contractor-RBP (C-RBP). (b) Model dynamics are reflected in their performance on Pathfinder-14. Segmentations evolve over time, as depicted by the colormap. While the BPTT-trained hGRU is accurate at N steps (red box), it fails when asked to process for longer (t=T=40, blue box). (c) Two-sample KS-tests indicate that the distance in state space between t=N and t=T hidden states is significantly greater for an hGRU trained with BPTT than an hGRU trained with C-BPTT or C-RBP. (n.s. = not significant).
Abstract
There is consensus that recurrent processes support critical visual routines in primate vision, from perceptual grouping to object recognition. These findings are consistent with a growing body of literature suggesting that recurrent connections improve generalization and learning efficiency on classic computer vision challenges. Why then, are current challenges dominated by feedforward networks? We posit that the effectiveness of recurrent vision models is bottlenecked by the widespread algorithm used for training them, "back-propagation through time" (BPTT), which has O(N) memory-complexity for training an N step model. Because of this, recurrent vision models cannot rival the enormous capacity of leading feedforward networks, nor compensate for this deficit by learning granular and complex visual routines. Here, we develop a new learning algorithm, "contractor recurrent back-propagation" (C-RBP), which achieves constant O(1) memory-complexity. We demonstrate that recurrent vision models trained with C-RBP learn long-range spatial dependencies in a synthetic contour tracing task that BPTT-trained models cannot. We further demonstrate that the leading feedforward approach to the large-scale Panoptic Segmentation MS-COCO challenge is improved when augmented with recurrent connections and trained with C-RBP. C-RBP is a general-purpose learning algorithm for any application that can benefit from expansive recurrent dynamics.